자주쓰는 명령어로 배우는 Pandas #3 : 데이터 조작하기
자주쓰는 명령어로 배우는 Pandas 2편에 이어 3편입니다. 이번에는 데이터를 조작해보겠습니다. 1편, 2편에서 작성했던 코드 결과들은 계속 유지되니 직접 실습을 따라 하고 싶으신 분들은 이전 시리즈를 참고해주세요.
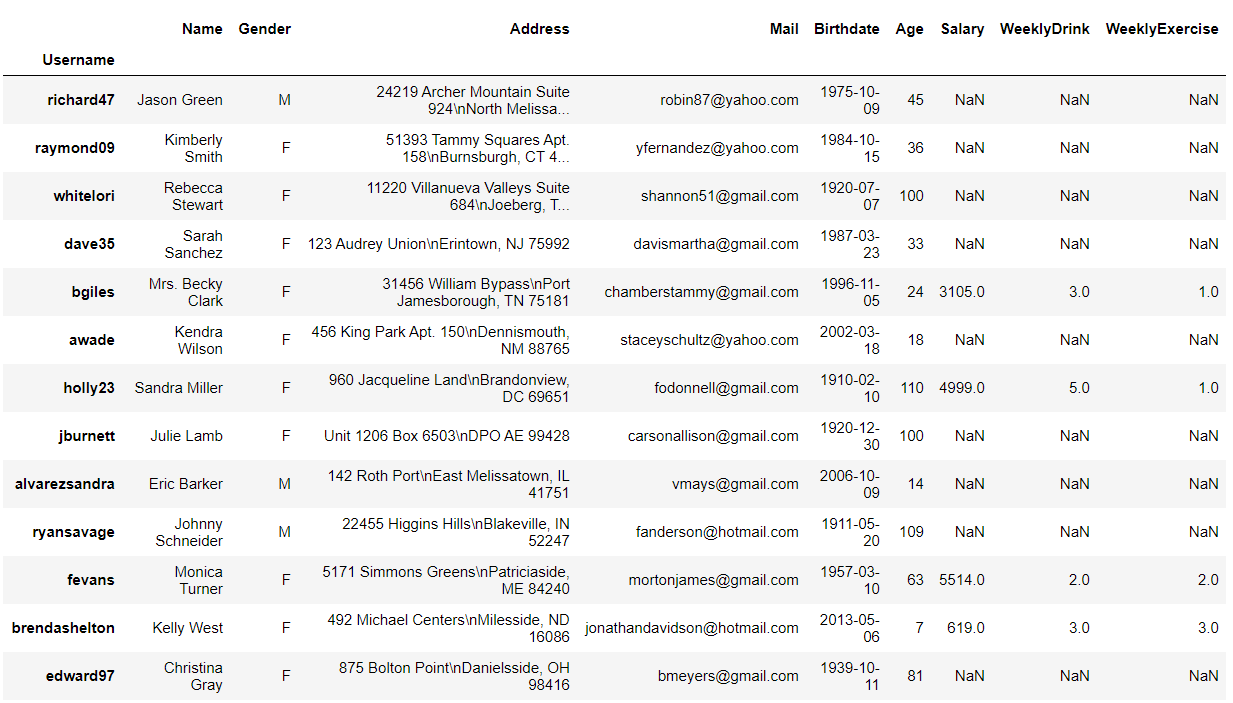
지난번 실습까지 잘 따라오셨다면, 아래와 같은 데이터 프레임을 가지고 있으실 겁니다.
df.head()실행결과
데이터 요약하기
우선 데이터를 조작하기에 앞서 DataFrame의 데이터를 요약하여 확인하는 방법을 알아보겠습니다.
데이터프레임의 각 컬럼별 타입 확인하기
데이터가 어떤 타입으로 이루어져 있는지 확인이 필요할 때가 있습니다. df.dtypes를 입력하면 데이터프레임의 타입을 확인할 수 있습니다.
df.dtypes아래 실행결과에서 object라고 되어있는 것은 문자열 타입이라고 생각하시면 되고 int64는 정수 float64는 소수형(?) 타입입니다. 여기서 64 이외에도 16, 32 등의 숫자를 붙일 수 있는데 더 큰 숫자를 쓸수록 더 큰 수를 입력하실 수 있다고 생각하시면 됩니다.
*8, 16, 32, 64를 데이터의 특성에 맞게 적절하게 할당해주면 DataFrame의 크기를 줄일 수 있습니다. 이와 관련해서 좀 더 알아보고 싶으신 분들은 이 블로그를 참고해주세요
실행결과

데이터프레임 타입 변경하기
DataFrame의 타입이 원하는 타입이면 좋겠지만, 생각했던 타입이 아닐 수도 있습니다. 이럴 때는 astype을 이용하면 데이터프레임의 타입을 변경할 수 있습니다.
여기서는, 데이터프레임의 크기를 줄이기 위해 int64를 int8로 변경하고, float64를 float32로 변경하겠습니다.
df = df.astype({"Age": "int8", "Salary": "float32", "WeeklyDrink": "float32", "WeeklyExercise": "float32"})
df.dtypes실행결과

*참고로, 위의 경우에 float를 int타입으로 변경할 수는 없습니다. NaN값이 포함되어 있는 경우 NaN값은 numpy에서 float으로 인식되기 때문입니다. Pndas 0.24.0 버전부터 실험적으로 numpy.nan 대신 pd.Na를 도입하는 시도를 하고 있으나 아직까지는 사용을 권장드리지는 않습니다. (참고)
기본적인 통계지표 확인하기
describe 메소드를 활용하면 숫자형 컬럼들에 대한 기본 통계지표를 확인할 수 있습니다.
df.describe()실행결과

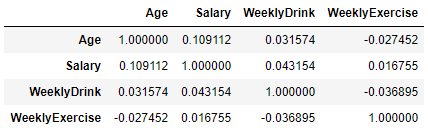
corr 메소드는 각 컬럼들 간의 상관관계를 쉽게 볼 수 있게 해 줍니다.
df.loc[:,["Age", "Salary","WeeklyDrink", "WeeklyExercise"]].corr()실행결과
NaN 핸들링
NaN데이터, 즉 결측치는 적절하게 핸들링해줄 필요가 있습니다. 데이터가 충분하다면, 결측치 데이터는 그냥 날려버리는 것도 옵션이 될 수 있고, 그렇지 않을 때는 적절하게 Interpolation을 해줘야 할 수도 있습니다.
NaN 제거
dropna 메소드를 이용하면 NaN값이 포함되어있는 데이터를 모두 제거할 수 있습니다.
df = df.dropna()
len(df)실행결과
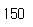
500개의 데이터가 150개를 남기고 모두 제거되었습니다.
일부 데이터가 NaN인 경우는 살려두고 모든 row가 다 NaN일 경우에만 제거하고 싶은 경우도 있습니다. 그럴 때는 df.dropna(how="all")로 써주시면 됩니다.
NaN 채우기
NaN값을 채우기 전에 다시 NaN값을 포함한 데이터프레임이 필요합니다. 그러기 위해서 일단 데이터를 추가해보겠습니다.
df2 = pd.DataFrame([fake.simple_profile() for _ in range(100)]).set_index("username")
df2.index.name = "Username"
df2.columns = ["Name", "Gender", "Address", "Mail", "Birthdate"]
df2['Age'] = pd.Timestamp.now().year - pd.to_datetime(df2["Birthdate"]).dt.year
df2 = df2.drop("Birthdate", axis=1)
df = pd.concat([df, df2])
df.tail()pd.concat메소드는 다른 두 개의 데이터프레임을 합칠 때 사용됩니다. 이때, 한쪽 데이터프레임에 컬럼이 존재하지 않으면 해당 컬럼의 값은 NaN으로 추가됩니다.
실행결과

데이터프레임은 준비되었으니 NaN값을 채워보겠습니다.
fillna 메소드를 사용하면 NaN값을 채울 수 있습니다. 해당 메소드에는 다양한 옵션이 있습니다. 자세한 옵션은 pandas API 문서를 확인해주세요.
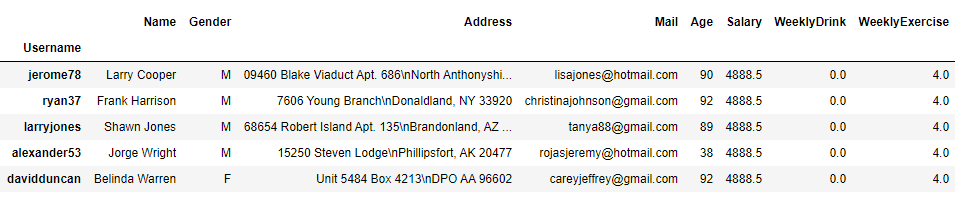
df["WeeklyDrink"] = df["WeeklyDrink"].fillna(0) # 0으로 채워넣기
df["WeeklyExercise"] = df["WeeklyExercise"].fillna(method="ffill") # NaN값이 나오기 전 값으로 뒤의 NaN값 채워넣기 (Forward Fill)
df["Salary"] = df["Salary"].fillna(df["Salary"].median()) # 중간값으로 채워넣기
df.tail()실행결과
좀 더 정교하게 결측치를 핸들링하고 싶다면 interpolate 메소드를 이용할 수도 있습니다. 자세한 내용은 pandas API 문서를 확인해주세요.
데이터 값 변경하기
Replace
replace 메소드를 활용하면 데이터의 값을 다른 값으로 변경할 수 있습니다.
# 'M'을 'male'로 'F'를 'female'로 변경
df["Gender"] = df["Gender"].replace({"M": "male", "F": "female"})
df.head()실행결과

이상으로 자주쓰는 명령어로 배우는 Pandas 3편을 마치겠습니다. 4편에서는 DataFrame에서 데이터를 필터링/마스킹하는 방법과 데이터에 함수를 적용하거나 그룹핑하는 방법에 대해 알아보겠습니다.
감사합니다.