안녕하세요! '자주 쓰는 명령어로 배우는 Polars' 시리즈의 두 번째 글입니다. 지난 글에서는 Polars의 주요 특징과 Pandas와의 차이점에 대해 알아보았는데요. 오늘은 본격적으로 Polars를 사용하여 데이터를 다루는 방법에 대해 알아보도록 하겠습니다.
데이터 분석의 첫걸음은 데이터를 불러오는 것부터 시작합니다. Polars는 다양한 포맷의 데이터를 효율적으로 처리할 수 있으며, 대용량 데이터 처리에 장점을 가지고 있습니다. 이번 포스트에서는 데이터를 불러오고 기본적인 조작을 하는 방법에 대해 자세히 알아보겠습니다. 😊
💡 여기서 사용하는 Polars 버전은 1.5입니다. polars 버전이 1 미만이면 예시 코드가 제대로 동작하지 않을 수 있습니다.
먼저 필요한 라이브러리를 임포트하겠습니다. (아직 설치를 안 하신 분들이 있다면 지난 글을 참고해서 먼저 설치해주세요 🛠️)
import polars as pl📚 다양한 포맷의 데이터 읽기
Polars는 다양한 데이터 소스로부터 데이터를 읽고 쓸 수 있습니다. CSV, JSON, Parquet과 같은 일반적인 파일 형식부터 S3, Azure Blob, BigQuery와 같은 클라우드 스토리지, 그리고 PostgreSQL, MySQL과 같은 데이터베이스까지 지원하고 있습니다. 여기서는 CSV와 Parquet 파일을 읽는 부분을 다뤄보겠습니다.
먼저 아래의 링크를 클릭해서 csv와 parquet파일을 받아줍시다.
1. CSV 파일 읽기
기본적인 csv 읽기
df = pl.read_csv("Pokemon.csv")
print(df)실행결과

데이터 타입을 지정하여 읽기
df = pl.read_csv(
"Pokemon.csv",
schema_overrides={
"Generation": pl.UInt8, # 세대는 6까지만 있어서 UInt8로 충분함
"Legendary": pl.Boolean, # 전설의 포켓몬 여부 (참/거짓)
"HP": pl.UInt16, # HP 값은 1-255 범위
"Attack": pl.UInt16, # 공격력 값은 5-190 범위
"Defense": pl.UInt16, # 방어력 값은 5-230 범위
"Sp. Atk": pl.UInt16, # 특수공격력 값은 10-194 범위
"Sp. Def": pl.UInt16, # 특수방어력 값은 20-230 범위
"Speed": pl.UInt16, # 스피드 값은 5-180 범위
}
)
print(df)실행결과
💡 CSV 파일 읽기 팁
- 큰 CSV 파일을 다룰 때는
low_memory=True옵션을 사용하면 메모리 사용량을 줄일 수 있습니다. (단, 읽기 성능이 떨어질 수 있습니다.)schema_overrides파라미터를 통해 컬럼의 데이터 타입을 미리 지정하면 읽기 속도 및 메모리 사용량을 최적화할 수 있습니다.columns파라미터로 필요한 컬럼만 선택적으로 읽을 수 있어 메모리 효율을 높일 수 있습니다.
2. Parquet 파일 읽기
Parquet은 컬럼 기반 저장 방식을 사용하는 파일 형식으로, 특히 빅데이터 처리에 최적화되어 있습니다.
Parquet 파일 읽기 부분을 CSV 예시처럼 기본적인 읽기와 최적화된 읽기로 나누어 보겠습니다:
df = pl.read_parquet("Pokemon.parquet")
print(df)실행결과

💡 read_csv와 read_parquet의 더 다양한 옵션이나, 다른 데이터 형식에 대한 API가 궁금하신 분들은 'Polars API 문서 - IO'와 'Polars 유저 가이드 - IO' 참고해 주세요.
💡 Lazy Evaluation을 위해서는read대신scan을 사용하면 됩니다.
🔍 데이터 살펴보기
데이터를 불러온 후에는 데이터의 특성을 파악하는 것이 중요합니다. Polars는 데이터를 빠르게 탐색할 수 있는 다양한 메서드를 제공합니다.
1. 기본 정보 확인
데이터프레임의 기본적인 특성을 파악하는 메서드들입니다. 데이터의 크기, 구조, 타입 등을 빠르게 확인할 수 있어요.
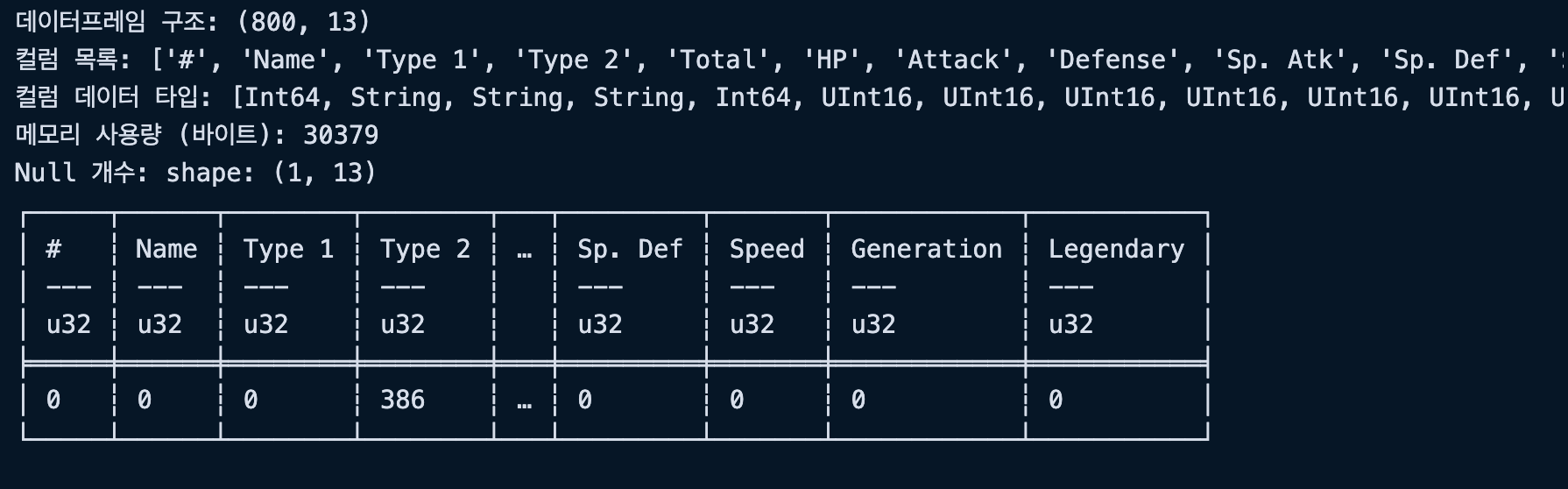
print("데이터프레임 구조:", df.shape)
print("컬럼 목록:", df.columns)
print("컬럼 데이터 타입:", df.dtypes)
print("메모리 사용량 (바이트):", df.estimated_size())
print("Null 개수:", df.null_count())실행결과
2. 데이터 미리 보기
대용량 데이터를 다룰 때는 전체 데이터를 한 번에 보기 어렵습니다. 이럴 때 데이터의 일부분만 확인할 수 있는 메서드들을 활용하면 좋습니다.
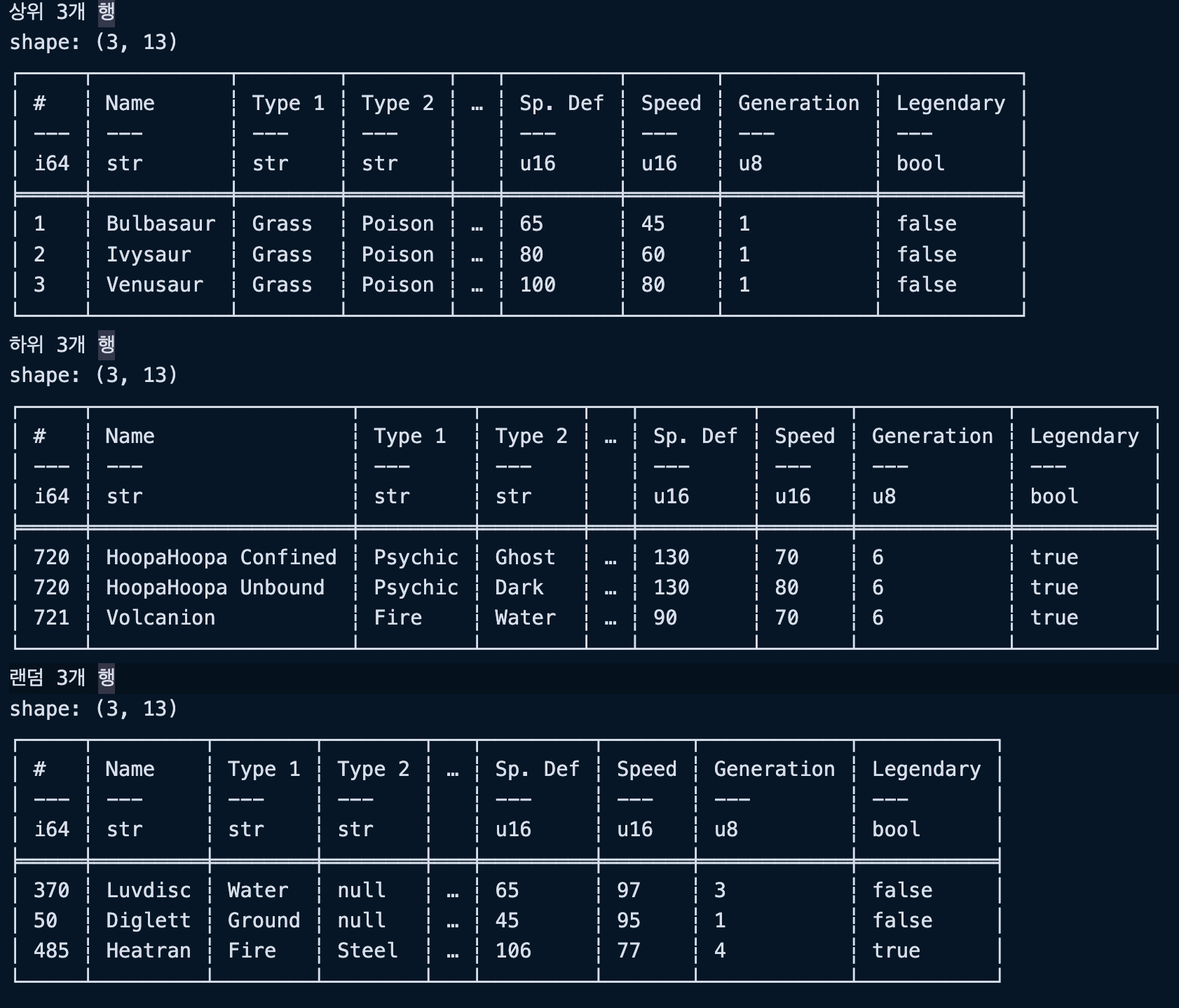
print("상위 10개 행")
print(df.head(10)) # 기본 값 5
print("하위 10개 행")
print(df.tail(10)) # 기본 값 5
print("랜덤 5개 행")
print(df.sample(5))실행결과
3. 기본 통계정보
데이터의 전반적인 특성을 파악하기 위한 통계 정보를 확인할 수 있는 메서드들입니다. 수치형 데이터의 분포와 특성을 빠르게 이해할 수 있어요.
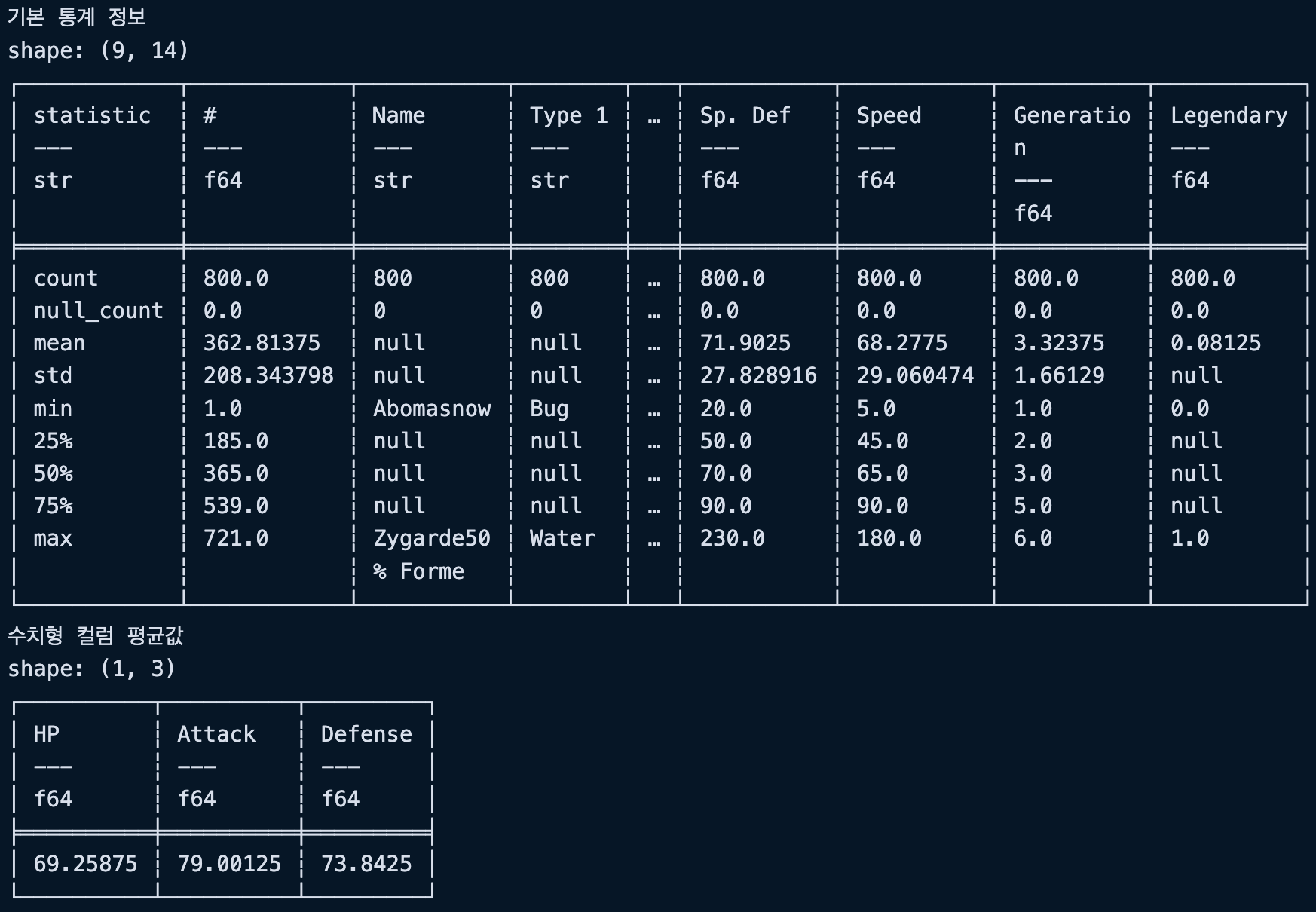
print("기본 통계 정보")
print(df.describe())
print("수치형 컬럼 평균값")
print(df.select(pl.col(["HP", "Attack", "Defense"])).mean())실행결과
이 외에도 다양한 통계 관련 메서드들이 있습니다.
기술통계량 관련
median(): 중앙값std(): 표준편차var(): 분산quantile(): 지정한 백분위수 값mode(): 최빈값
집계 관련
sum(): 합계min(): 최솟값max(): 최댓값count(): 개수
⚡ 컬럼 선택 및 조작하기
Polars는 다양한 방식으로 컬럼을 선택하고 조작할 수 있습니다.
1. 컬럼 선택하기
select 메서드를 사용하면 원하는 컬럼을 선택할 수 있습니다.
df_selected = df.select(["Name", "Type 1", "HP"])
print(df_selected.head(3))실행결과

2. 특정 컬럼 제외하고 선택하기
pl.col("*")와 exclude메서드를 활용하면 특정 컬럼을 제외할 수 있습니다.
df_without = df.select(pl.col("*").exclude(["Generation", "Legendary"]))
print(df_without.head(3))실행결과
3. 고급 컬럼 선택 기능
polars.selectors 모듈을 사용하면 '데이터 타입', '정규 표현식', '위치', '패턴' 등을 활용한 컬럼 선택을 할 수 있습니다.
import polars.selectors as cs # 컬럼 선택을 위한 특별한 모듈
# 데이터 타입별 선택
numeric_cols = df.select(cs.numeric())
string_cols = df.select(cs.string())
# 정규표현식을 사용한 선택
type_cols = df.select(pl.col("^Type.*$")) # "Type"으로 시작하는 모든 컬럼
# 패턴 매칭을 통한 선택
cols_with_type = df.select(cs.contains("Type")) # "Type"이 포함된 컬럼들
print(nueric_cols.head(1))
print(string_cols.head(1))
print(type_cols.head(1))
print(cols_with_type.head(1))실행결과

4. 컬럼 추가 및 변환
with_columns 메서드는 새로운 컬럼을 추가하거나 기존 컬럼을 변환할 때 사용합니다. 특히 여러 컬럼을 한 번에 처리할 수 있어 매우 유용해요.
기본적인 컬럼 추가/변환
# 단일 컬럼 추가
df_with_new = df.with_columns([
(pl.col("Attack") + pl.col("Defense")).alias("TotalDefense")
])
# 여러 컬럼 동시에 추가
df_with_multiple = df.with_columns([
(pl.col("Attack") + pl.col("Defense")).alias("TotalDefense"),
(pl.col("HP") * 2).alias("DoubleHP"),
])
print(df_with_new.head(3))
print(df_with_multiple.head(3))실행결과
💡 with_columns는 기존 컬럼과 같은 이름의 새 컬럼을 만들면 자동으로 기존 컬럼을 대체합니다. 이를 활용하면 기존 컬럼을 변환할 때 유용합니다.
여기까지 Polars의 기본적인 데이터 읽기 및 조작 방법들에 대해 알아보았습니다. Polars의 강점인 성능 최적화와 메모리 효율성은 실제 대규모 데이터를 다룰 때 큰 도움이 될 거예요.
다음 글에서는 데이터 필터링, 그룹화 등 더 깊이 있는 데이터 조작 방법을 다뤄보겠습니다. 읽어주셔서 감사합니다! 🙇♂️🙇
📚 참고
'개발 > 파이썬' 카테고리의 다른 글
| Polars로 데이터 그룹화와 집계 📊 - 자주쓰는 명령어로 배우는 Polars #4 (0) | 2024.11.23 |
|---|---|
| Polars로 데이터 필터링 및 정렬하기 - 자주 쓰는 명령어로 배우는 Polars #3 (0) | 2024.11.09 |
| Polars 시작하기 (소개 및 설치) - 자주쓰는 명령어로 배우는 Polars #1 (0) | 2024.10.12 |
| poetry와 github actions를 활용한 파이썬 라이브러리 배포 자동화 (2) | 2024.04.13 |
| SEO를 위한 sitemapr 라이브러리 소개: 구글에 서비스 페이지를 알려주자. (25) | 2024.03.16 |



