자주 쓰는 명령어로 배우는 Polars #3: 데이터 필터링과 정렬 🔍
안녕하세요! '자주 쓰는 명령어로 배우는 Polars' 시리즈의 세 번째 글입니다. 지난 글에서는 데이터를 불러오고 기본적으로 조작하는 방법에 대해 알아보았는데요. 오늘은 필터링과 정렬 기능에 대해 알아보도록 하겠습니다.
데이터 분석에서 필터링과 정렬은 매우 중요한 작업입니다. Polars는 이러한 작업을 빠르고 직관적으로 수행할 수 있도록 다양한 기능을 제공하고 있는데요. 실제 데이터를 활용한 예제를 통해 살펴보도록 하겠습니다. 😊
💡 여기서 사용하는 Polars 버전은 1.5입니다. polars 버전이 1 미만이면 예시 코드가 제대로 동작하지 않을 수 있습니다.
먼저 필요한 라이브러리를 임포트하고 예제 데이터를 불러와 보겠습니다. (아직 설치를 안 하신 분들이 있다면 지난 글을 참고해서 먼저 설치해 주세요 🛠️)
예제 데이터는 아래 파일을 다운받아주세요.
0. polars 임포트 및 데이터 불러오기
import polars as pl
# 데이터 불러오기
df = pl.read_csv("Pokemon.csv")1. 기본 필터링 🎯
Polars에서 데이터 필터링은 filter 메서드를 사용합니다. 필터링 조건은 pl.col()을 사용하여 표현하며, 다양한 비교 연산자를 활용할 수 있습니다.
단일 조건 필터링
# HP가 100 이상인 포켓몬 찾기
high_hp = df.filter(pl.col("HP") >= 100)
print("HP가 100 이상인 포켓몬:")
print(high_hp.select(["Name", "HP", "Type 1"]).head())실행결과

다중 조건 필터링
여러 조건을 조합할 때는 &(and), |(or), ~(not) 연산자를 사용합니다:
# 불꽃 타입이면서 공격력이 100 이상인 포켓몬
strong_fire = df.filter(
(pl.col("Type 1") == "Fire") & (pl.col("Attack") >= 100)
)
print("\n불꽃 타입 & 공격력 100 이상:")
print(strong_fire.select(["Name", "Type 1", "Attack"]).head())실행결과
# 전설의 포켓몬이거나 HP가 150 이상인 포켓몬
special = df.filter(
pl.col("Legendary") | (pl.col("HP") >= 150)
)
print("\n전설의 포켓몬 or HP 150 이상:")
print(special.select(["Name", "HP", "Legendary"]).head())실행결과
# 불꽃 타입이 아니면서 물 타입도 아닌 포켓몬
not_fire_water = df.filter(
~(pl.col("Type 1").is_in(["Fire", "Water"]))
)
print("\n불꽃 타입이 아니면서 물 타입도 아닌 포켓몬:")
print(not_fire_water.select(["Name", "Type 1"]).head())실행결과
Null 값 필터링
Polars에서는 is_null()과 is_not_null() 메서드를 사용하여 null 값을 처리할 수 있습니다:
# Type 2가 없는 (단일 타입) 포켓몬
single_type = df.filter(pl.col("Type 2").is_null())
print("\n단일 타입 포켓몬:")
print(single_type.select(["Name", "Type 1", "Type 2"]).head())실행결과
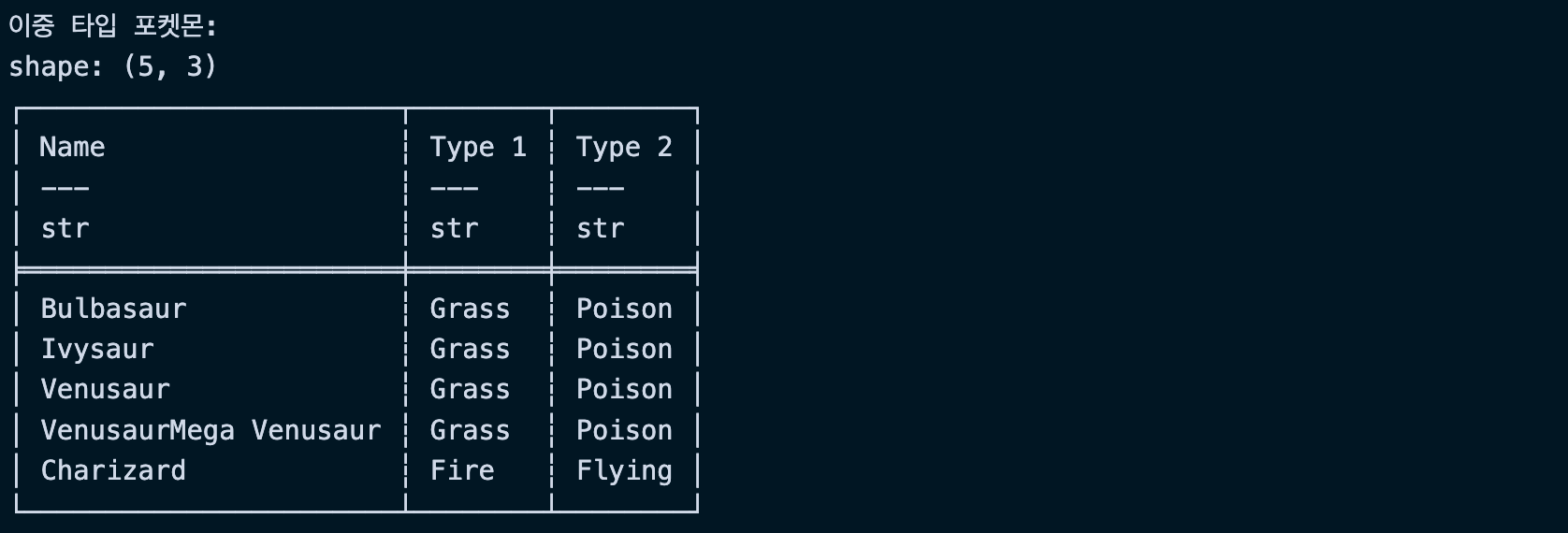
# Type 2가 있는 (이중 타입) 포켓몬
dual_type = df.filter(pl.col("Type 2").is_not_null())
print("\n이중 타입 포켓몬:")
print(dual_type.select(["Name", "Type 1", "Type 2"]).head())실행결과
2. 다양한 필터링 기법 더 알아보기 🚀
is_in을 활용한 필터링
특정 값들의 목록에 포함되는지 확인할 때는 is_in() 메서드를 사용합니다:
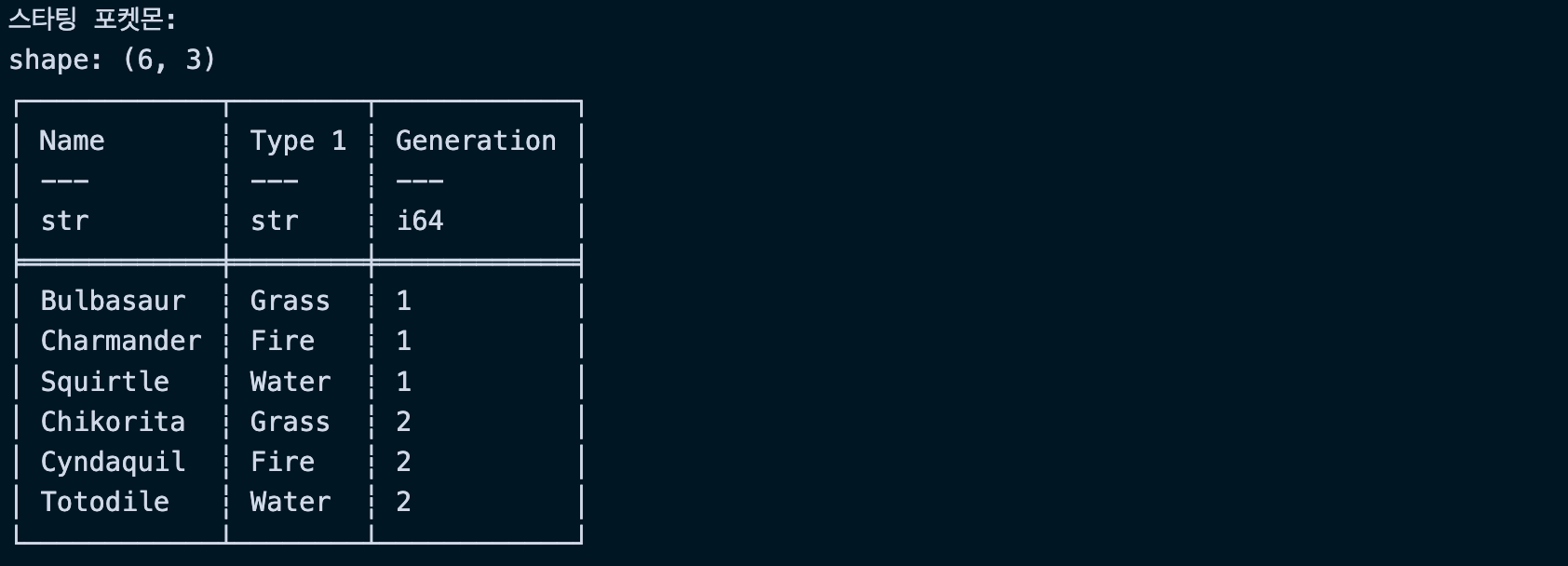
# 스타팅 포켓몬들 찾기
starters = ["Bulbasaur", "Charmander", "Squirtle", "Chikorita", "Cyndaquil", "Totodile"]
starter_pokemon = df.filter(pl.col("Name").is_in(starters))
print("스타팅 포켓몬:")
print(starter_pokemon.select(["Name", "Type 1", "Generation"]))실행결과
문자열 패턴 매칭
문자열 패턴을 이용한 필터링은 str 네임스페이스의 메서드들을 활용합니다:
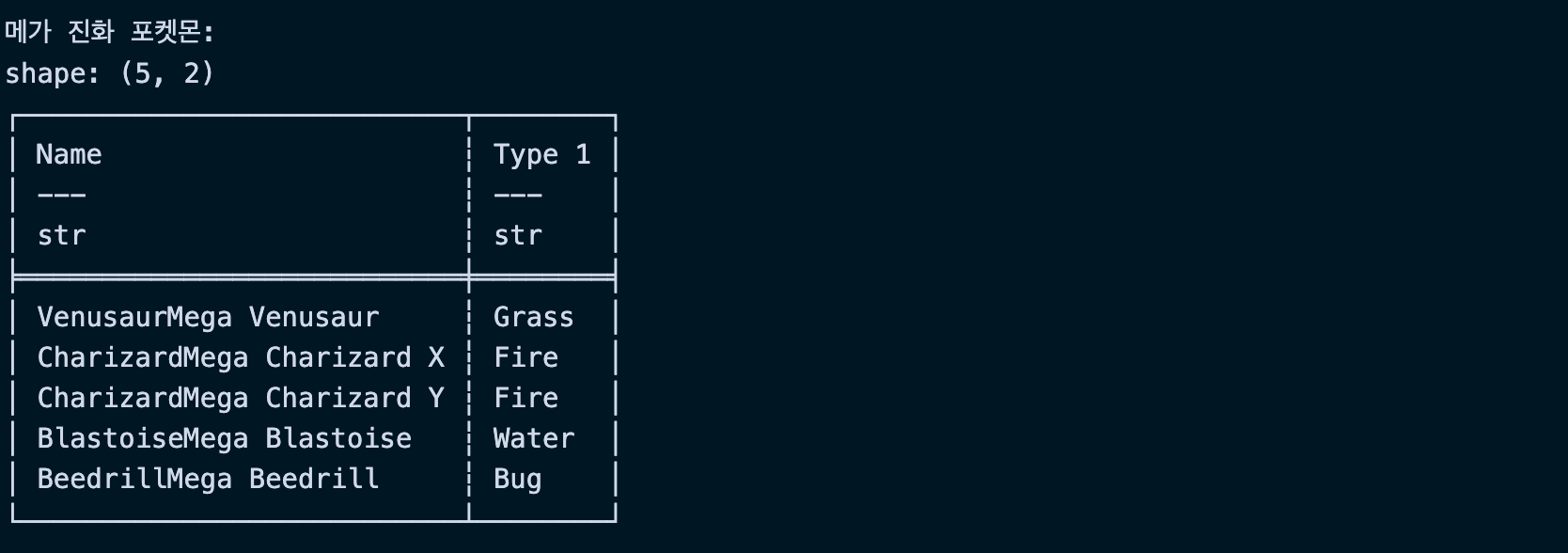
# 이름에 'Mega'가 포함된 포켓몬
mega_pokemon = df.filter(pl.col("Name").str.contains("Mega"))
print("\n메가 진화 포켓몬:")
print(mega_pokemon.select(["Name", "Type 1"]).head())실행결과
# 이름이 'D'로 시작하는 포켓몬
d_pokemon = df.filter(pl.col("Name").str.starts_with("D"))
print("\nD로 시작하는 포켓몬:")
print(d_pokemon.select(["Name"]).head())실행결과

정규표현식 활용
더 복잡한 패턴 매칭이 필요할 때는 정규표현식을 사용할 수 있습니다:
# 이름에 숫자가 포함된 포켓몬
numbered = df.filter(pl.col("Name").str.contains(r"\d"))
print("\n이름에 숫자가 있는 포켓몬:")
print(numbered.select(["Name"]).head())
# 'mega'로 시작하거나, 'X' 또는 'Y'로 끝나는 포켓몬
complex_pattern = df.filter(pl.col("Name").str.contains(r"(^[Mm]ega|[XY]$)"))
print("\n'mega'로 시작하거나, 'X' 또는 'Y'로 끝나는 포켓몬:")
print(complex_pattern.select(["Name"]).head())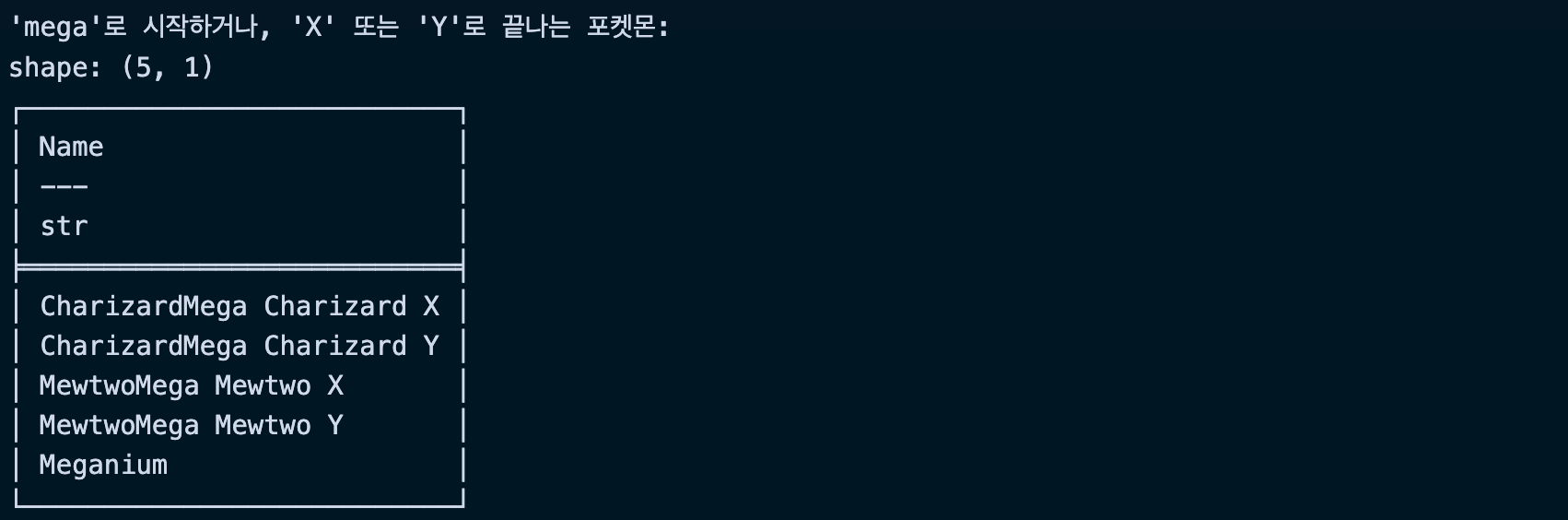
💡 Polars 데이터 필터링 팁
- 복잡한 필터링 조건을 작성할 때는 가독성을 위해 조건을 변수로 분리해 보세요. 재사용성도 높아지고 디버깅도 쉬워집니다.
condition1 = pl.col("col1") > 0
condition2 = pl.col("col2").is_not_null()
df.filter(condition1 & condition2)- 필터링 결과가 예상과 다르다면
describe()나glimpse()를 활용하여 데이터를 먼저 살펴보세요. 특히 대소문자나 공백 차이로 인한 문제가 자주 발생합니다. - 필터링 조건이 복잡할 때는
select()와with_columns()로 임시 컬럼을 만들어 활용해보세요. 조건식이 단순해지고 로직을 이해하기 쉬워집니다. - 문자열 필터링에서
contains()나starts_with()등은 대소문자를 구분합니다. 대소문자를 무시하려면str.to_lowercase()를 먼저 적용하세요.
3. 데이터 정렬하기 📊
Polars는 sort 메서드를 통해 단순한 정렬부터 복잡한 정렬까지 다양한 정렬 기능을 제공합니다.
단일 컬럼 기준 정렬
sort 메서드를 사용하여 특정 컬럼을 기준으로 정렬할 수 있습니다:
# HP 기준 내림차순 정렬
hp_sorted = df.sort("HP", descending=True)
print("HP 기준 상위 5마리:")
print(hp_sorted.select(["Name", "HP"]).head())실행결과

# 공격력 기준 오름차순 정렬
attack_sorted = df.sort("Attack")
print("\n공격력 기준 하위 5마리:")
print(attack_sorted.select(["Name", "Attack"]).head())실행결과

다중 컬럼 기준 정렬
여러 컬럼을 기준으로 정렬할 때는 sort 메서드에 리스트를 전달합니다:
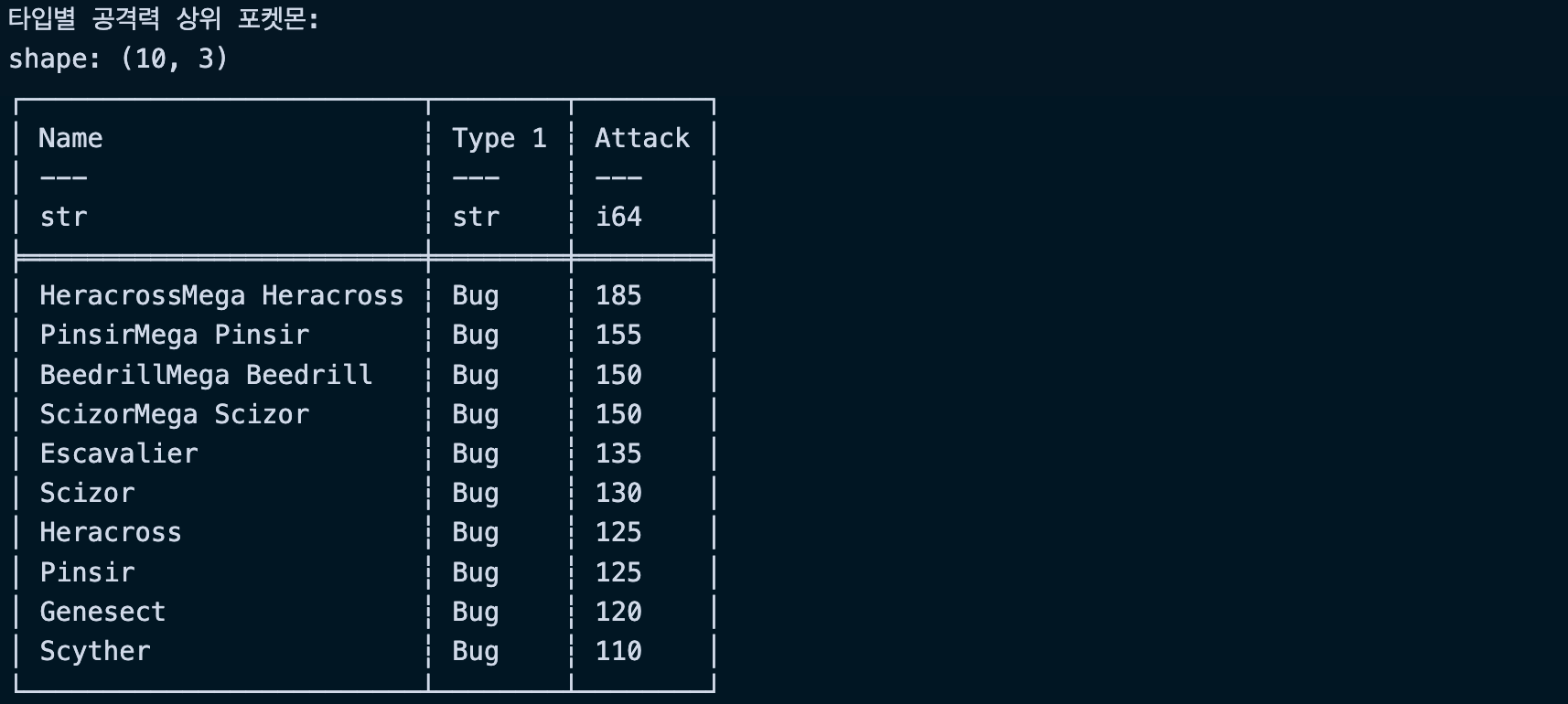
# Type 1으로 먼저 정렬하고, 같은 타입 내에서는 Attack으로 정렬
type_attack_sorted = df.sort(["Type 1", "Attack"], descending=[False, True])
print("\n타입별 공격력 상위 포켓몬:")
print(type_attack_sorted.select(["Name", "Type 1", "Attack"]).head(10))실행결과
표현식을 활용한 정렬
sort 메서드에 표현식을 전달하여 복잡한 정렬 조건을 적용할 수 있습니다:
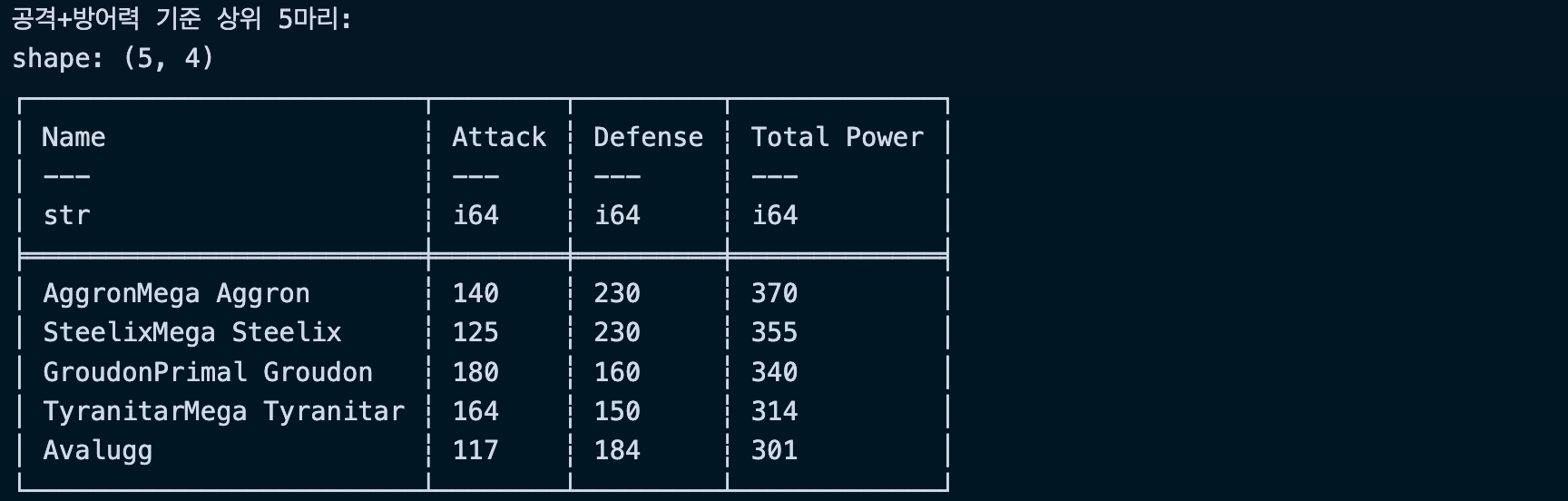
# 공격력과 방어력의 합계를 기준으로 정렬
total_power_expr = (pl.col("Attack") + pl.col("Defense")).alias("Total Power")
power_sorted = (
df
.sort(total_power_expr, descending=True)
.select([
"Name",
"Attack",
"Defense",
total_power_expr
])
)
print("\n공격+방어력 기준 상위 5마리:")
print(power_sorted.head())실행결과
🎯 실전 예제: 최강의 포켓몬 찾기
필터링과 정렬 기능을 활용해서 조건에 맞는 "최강의 포켓몬"을 찾아보겠습니다:
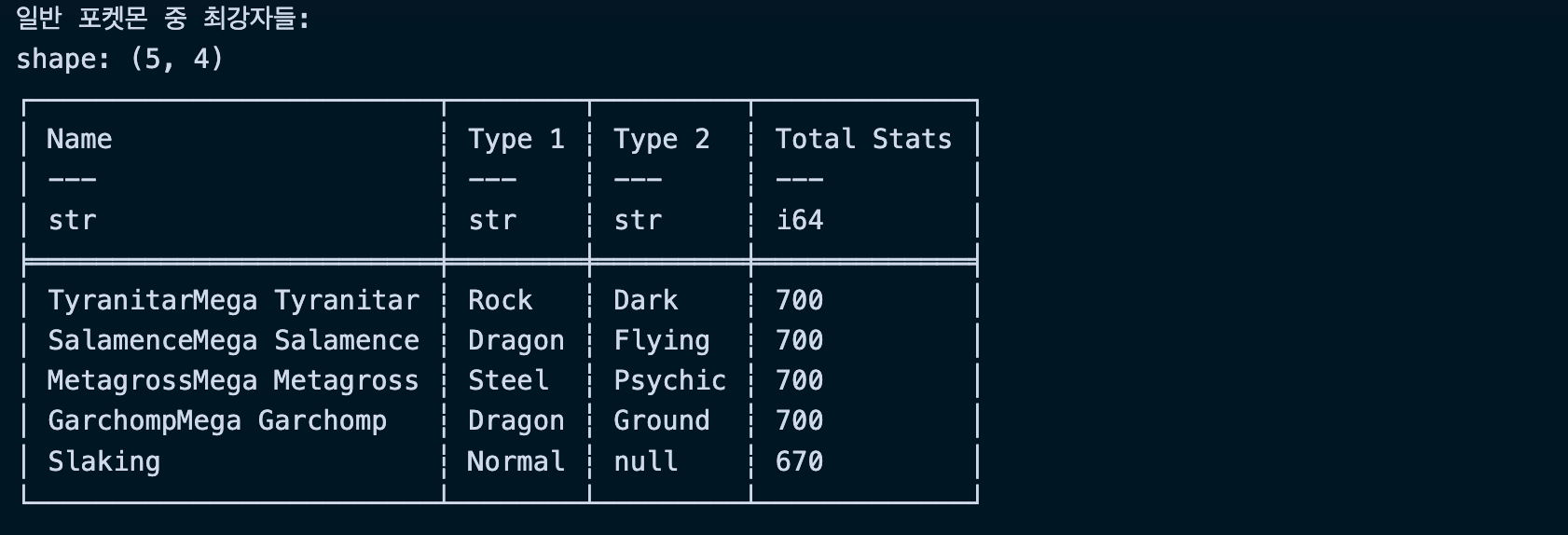
strongest = (
df
# 전설의 포켓몬 제외
.filter(~pl.col("Legendary"))
# 총 스탯 계산
.with_columns(
(
pl.col("HP")
+ pl.col("Attack")
+ pl.col("Defense")
+ pl.col("Sp. Atk")
+ pl.col("Sp. Def")
+ pl.col("Speed")
).alias("Total Stats")
)
# 총 스탯 기준 정렬
.sort("Total Stats", descending=True)
# 필요한 컬럼만 선택
.select(["Name", "Type 1", "Type 2", "Total Stats"])
)
print("일반 포켓몬 중 최강자들:")
print(strongest.head())실행결과
이번 글에서는 Polars의 필터링과 정렬 기능에 대해 자세히 알아보았습니다. 여러분도 다양한 방식으로 응용해서 여러분들의 문제를 해결해 보시기를 바랍니다! 🚀
다음 글에서는 데이터 그룹화와 집계 함수 사용법에 대해 알아보도록 하겠습니다. 긴 글 읽어주셔서 감사합니다! 😊
📚 참고자료
'개발 > 파이썬' 카테고리의 다른 글
| 데이터 결합과 재구조화 🔄 - 자주 쓰는 명령어로 배우는 Polars #5 (1) | 2024.12.08 |
|---|---|
| Polars로 데이터 그룹화와 집계 📊 - 자주쓰는 명령어로 배우는 Polars #4 (0) | 2024.11.23 |
| Polars로 데이터 불러오기 및 조작하기 - 자주 쓰는 명령어로 배우는 Polars #2 (1) | 2024.10.26 |
| Polars 시작하기 (소개 및 설치) - 자주쓰는 명령어로 배우는 Polars #1 (0) | 2024.10.12 |
| poetry와 github actions를 활용한 파이썬 라이브러리 배포 자동화 (2) | 2024.04.13 |


